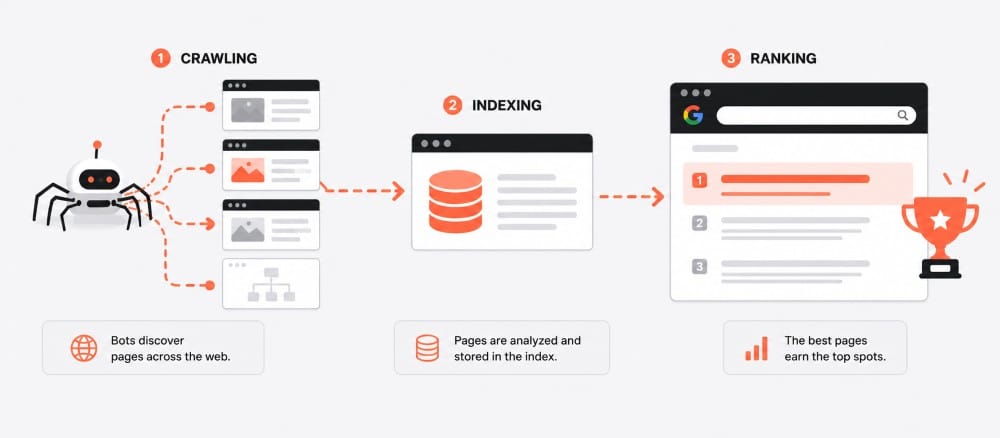
Finding something on Google feels instant. Type a search, hit enter, and results show up in seconds.
Behind that, there’s a pretty structured process happening.
Search engines don’t search the entire internet every time you type a query. They rely on systems that discover, store, and organize content ahead of time.
That process comes down to three core steps:
-
Crawling: Discovering content on the internet
-
Indexing: Organizing and storing that content
-
Ranking: Sorting the results based on relevance and quality
Search engines work by finding content, storing it, and then deciding what to show based on relevance and quality.
Once you understand that, SEO starts to make a lot more sense.
What is a search engine?
At its core, a search engine is a system that finds and organizes information from the web, then delivers the most relevant results when someone searches.
Google is the obvious example, handling billions of searches every day, but it’s not the only one. Bing, Yahoo, and DuckDuckGo all work in similar ways.
They’re all trying to do the same thing:
Return the most useful result for a given search, as quickly as possible.
To do that, they rely on crawling, indexing, and ranking.
What is crawling in SEO?
Crawling is the search engine’s way of exploring the internet.
Search engines use bots (often called crawlers or spiders) to move through the web and find pages. They start with known URLs, then follow links to find new ones.
If a page isn’t crawled, it can’t show up in search results.
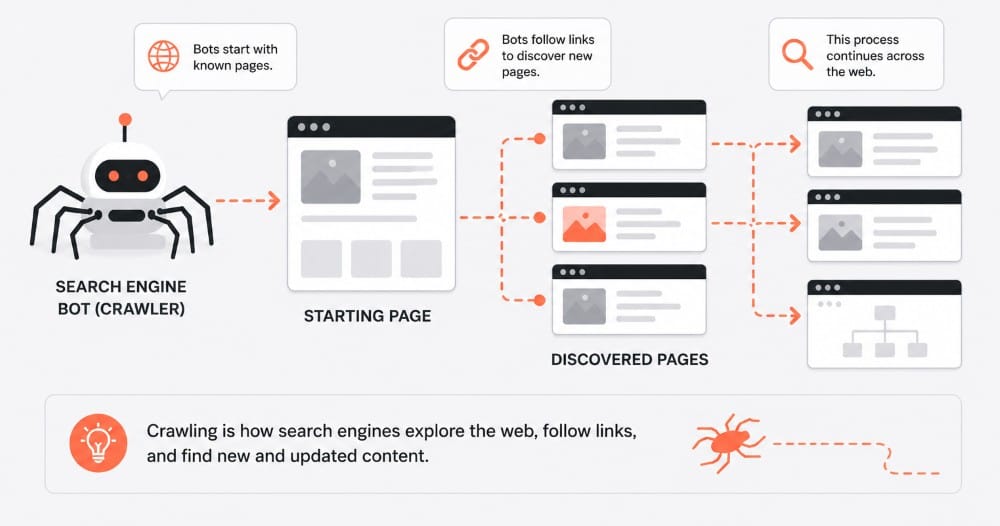
How crawling works
- Crawlers start with a list of known pages
- They follow links to discover new pages
- They download the page content
- They send that data back to be processed
What can block crawling
- Pages blocked by robots.txt
- Poor internal linking
- Large sites with limited crawl budget
- Content that only loads with heavy JavaScript
If your pages aren’t being discovered by Google, nothing else matters.
What is indexing in SEO?
Indexing is how search engines store and organize content after it’s crawled.
Once a page is discovered, the search engine analyzes it and decides whether it’s worth keeping.
If a page isn’t indexed, it won’t appear in search results.
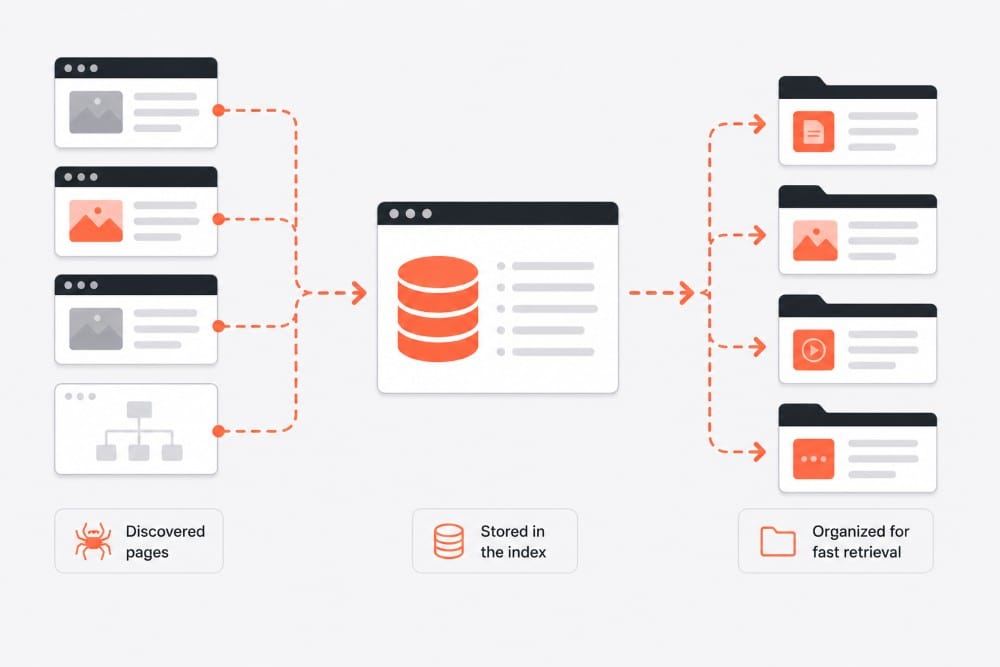
What happens during indexing
-
- The content is analyzed (text, images, metadata)
- Topics and keywords are identified
- The page is added to the search index
Think of the index like a giant database of pages Google can pull from.
Why pages don’t get indexed
-
- Thin or low-value content
- Duplicate pages
- Technical issues
- Lack of internal links
Indexing is where a lot of SEO problems show up. A page can exist, but still not be eligible to rank.
How ranking works in search engines
Ranking is how search engines decide which pages to show first.
When you search something, Google isn’t scanning the web live. It’s pulling from its index and sorting results based on relevance and quality.
Ranking determines which pages show up first, and which get ignored.
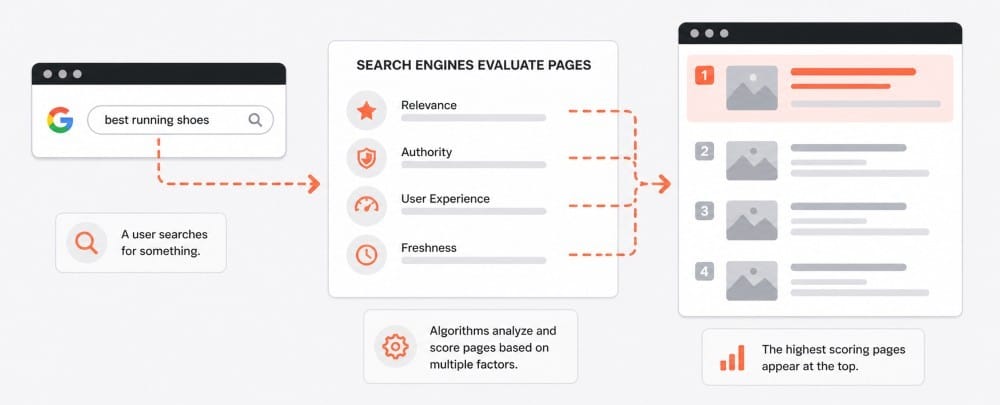
Core ranking factors:
-
Relevance: Does the page match the search intent?
-
Quality: Is the content useful and trustworthy?
-
Authority: Do other sites link to it?
-
User experience: Is the page fast and easy to use?
There are hundreds of other signals involved, but most of them tie back to those ideas.
How search engine algorithms affect rankings
Algorithms are the systems that decide how results are ranked.
They’re constantly updated, and they’re focused on one goal: showing the most helpful content for each search.
Modern algorithms rely heavily on:
-
- Understanding intent
- Evaluating content quality
- Measuring user behavior
This is why older tactics like keyword stuffing don’t work anymore.
What actually impacts rankings
There’s no single ranking factor that decides everything. But a few things consistently matter:
-
Content Quality: Unique, helpful, well-structured writing that serves a purpose.
-
Backlinks: Links from credible, relevant websites.
-
User Experience (UX): Fast-loading pages, mobile optimization, and easy navigation.
-
Technical SEO: Proper use of title tags, meta descriptions, clean URLs, and structured data.
-
Social signals: Shares, likes, and overall engagement can be small but helpful trust indicators.
No one factor works on it’s own. It’s the combination that matters.
How to improve your SEO based on this
Once you understand crawling, indexing, and ranking, the next step is applying it.
On-Page SEO
-
Keyword placement: Use natural language; don’t force it.
-
Meta tags: Write clear, engaging titles and descriptions.
-
Internal linking: Help users (and crawlers) easily move through your site.
-
Content quality: Focus on solving problems, not just ranking for terms.
If you’re just starting out, following these simple SEO tips for beginners can dramatically improve your visibility without feeling overwhelming.
Technical SEO
-
Speed matters: Optimize images, minimize scripts, and use caching.
-
Mobile first: Your site should look and perform great on phones.
-
Crawlability: Check your robots.txt and use a clean site structure.
-
Structured data: Add schema markup where it makes sense (like for blog posts, products, reviews).
Off-Page SEO
-
Build high-quality links: Focus on getting backlinks from reputable sites in your industry.
-
Leverage social media: Share your content where your audience is active.
-
Local SEO: If you serve a specific area, optimize your Google Business Profile and local citations.
Final Thoughts
Search engines aren’t guessing.
They’re following a process.
Content gets found through crawling, stored through indexing, and surfaced through ranking.
If you make it easy for search engines to do those three things, your chances of showing up improve.
That’s really what SEO comes down to.
Let’s grow your traffic together
Have an SEO question or need help with a project? Whether you’re a small business or a national brand, I’ll help you rank higher and convert more.
